A faster, cheaper Claude Code alternative with automatic provider failover using Hermes Agent
Posted on April 15, 2026 from Kalama, WashingtonAfter yet another Claude Code outage that lasted multiple hours, I decided to find out what it actually takes to replace it. Specifically: what does running Hermes Agent (Nous Research's open-source, self-improving agent framework) with open and open-weight models via hosted inference providers actually look like in practice, and how does it stack up against Claude Code on the Max 20x plan?
TL;DR: For the best balance of quality and latency, Qwen3.6 Plus via Fireworks serverless (~$0.56/hr, quality 8.7) is the top pick: only 0.5 points behind Claude Code with lower latency than any aggregator. If cost matters more than latency, Qwen3.6 Plus via OpenRouter drops to $0.21/hr at a small latency penalty. For pure budget, DeepSeek V3.2 via DeepSeek API ($0.09/hr) is hard to argue with. For the genuinely hard tasks like complex multi-file refactors where first-try-right matters, stick with Claude Code. The hybrid approach (open models for most tasks, Claude Code for escalation) is what I'd actually run.
This post lays out the full matrix: quality scores, inference speed benchmarks, cost-per-hour, quality-per-dollar ratios, and honest tradeoffs.
Why Hermes Agent
Three things make Hermes Agent (v0.9.0, April 2026) the right harness for this comparison. First, it works with any OpenAI-compatible endpoint, so the same agent setup runs across every provider and model in this post. Second, it has a native hermes tool-call parser that Qwen 2.5/3 and Hermes 3 models support out of the box, meaning the models that matter most here have zero tool-call parsing overhead. Third, its fallback_model feature now uses structured API error classification to distinguish rate limits from auth failures from server errors before deciding whether to fail over — so it doesn't thrash providers on transient errors, and it does switch cleanly when it needs to.
Two v0.9.0 additions are directly relevant to coding work. Background process monitoring (watch_patterns) lets the agent watch build or test output for specific patterns and react in real time — no polling, no manual "did it finish?" turns. And a context budget overhaul prevents the agent from stopping mid-task on long sessions, which matters when you're doing multi-file work that runs deep into the context window.
The honest caveat: Hermes Agent is a generalist framework, not a purpose-built coding agent like Claude Code. Its SWE-bench performance is a range (~40–80%) depending on the backend model, not a fixed number.
The quality baseline: Claude Code Max 20x
Before comparing anything, we need the baseline. Claude Code on the Claude Max 20x plan ($200/mo flat) running Sonnet 4.6:
How quality scores work: Throughout this post, quality scores (1–10) are a weighted composite of five factors:
- SWE-bench Verified (30%)
- Tool-use reliability (25%)
- Multi-file edit coherence (15%)
- Aider Polyglot (15%)
- Hermes ecosystem compatibility (15%)
These are scores for the model running through Hermes Agent, not raw model benchmarks. The Claude Code baseline is measured through its own harness using the same composite methodology, so the scores are comparable but the measurement context differs. Treat differences smaller than ~0.3 points as within measurement noise. Full methodology is at the bottom.
| Metric | Value |
|---|---|
| Monthly cost | $200 flat |
| Effective $/hr (at 176 coding hrs/mo) | ~$1.14 |
| Quality score (composite) | 9.2/10 |
| SWE-bench Verified | ~80% |
| Tool-use reliability | 10/10 |
| TTFT (time to first token) | ~500ms |
| Output tok/s | ~90 |
| 30-turn task wall-clock | ~8 min |
This is the bar. Everything below gets measured against it.
Quality vs inference speed
For me, this is the most important chart. The X-axis is output tokens per second (how fast the model generates code), the Y-axis is the composite coding quality score. Bubble size indicates SWE-bench percentage. Upper-right quadrant is the ideal zone.
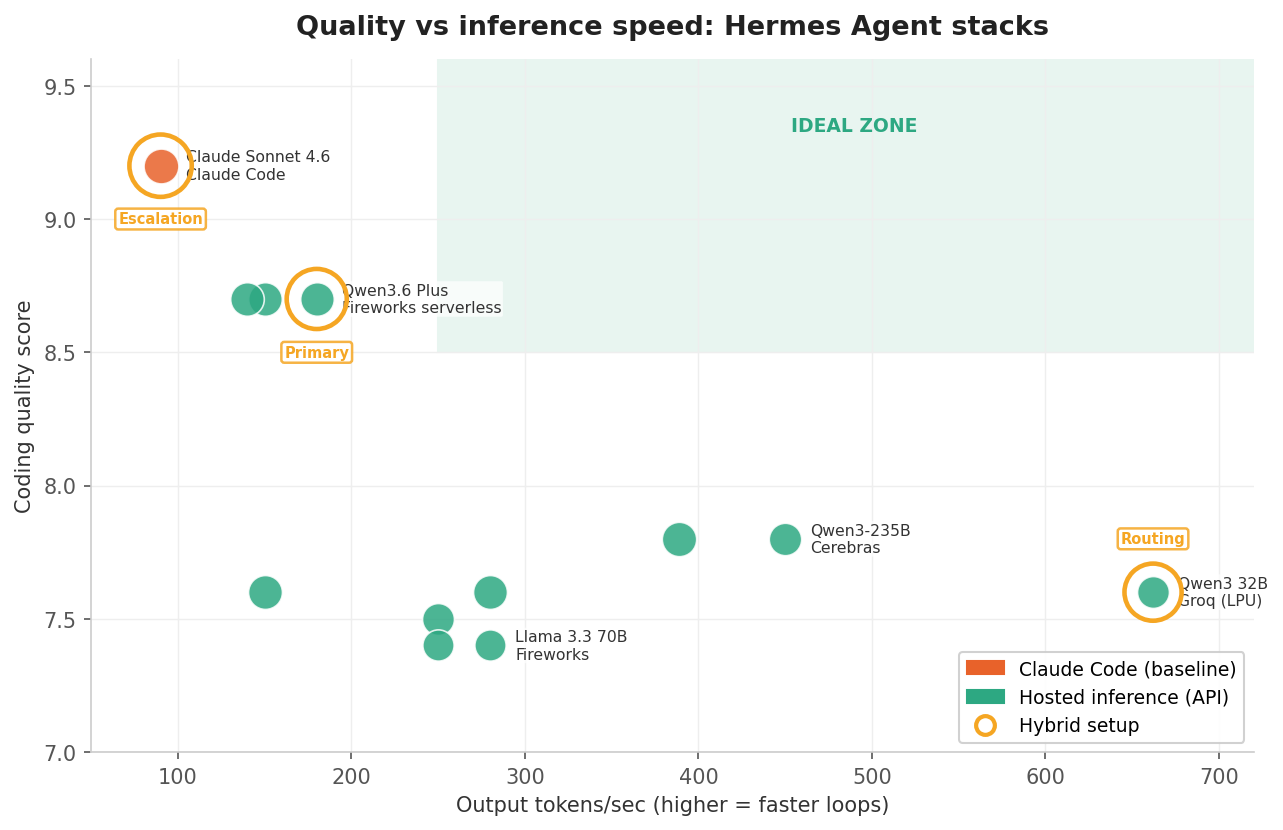
Key observations:
- Claude Code sits in the upper-left. Highest quality, but also among the slowest at ~90 tok/s. You're paying for correctness.
- Qwen3.6 Plus via OpenRouter occupies the sweet spot: quality 8.7 (0.5 points behind Claude) at ~150 tok/s, at roughly a fifth of the cost.
- Cerebras with Qwen3-235B and Groq with Qwen3 32B are the speed demons in the lower-right. Fast but lower quality.
- Kimi K2.5 on Fireworks is worth a closer look if your work is bug-fix or issue-driven. Its SWE-bench score (~77%) is strong, and its composite quality (7.8) understates it because the
llama3_jsontool format creates friction on tool-use reliability and Hermes compatibility — if SWE-bench-style tasks are most of what you do, it punches above that number. - MiniMax M2.5 via OpenRouter has the highest SWE-bench Verified score in the table (~80%, matching Claude Code), but its real-world Hermes Agent usage is low relative to that benchmark result. The reasoning overhead (~1.8s TTFT) also makes it feel slow compared to everything else in this tier. Worth evaluating if your work maps closely to SWE-bench-style tasks, but verify it on your own workload before committing.
Speed and quality tell you what you're getting. Cost tells you what you're paying for it.
Quality-per-dollar vs Claude Code
This normalizes everything to a single question: for each dollar I spend, how much coding quality am I getting compared to Claude Code Max 20x?
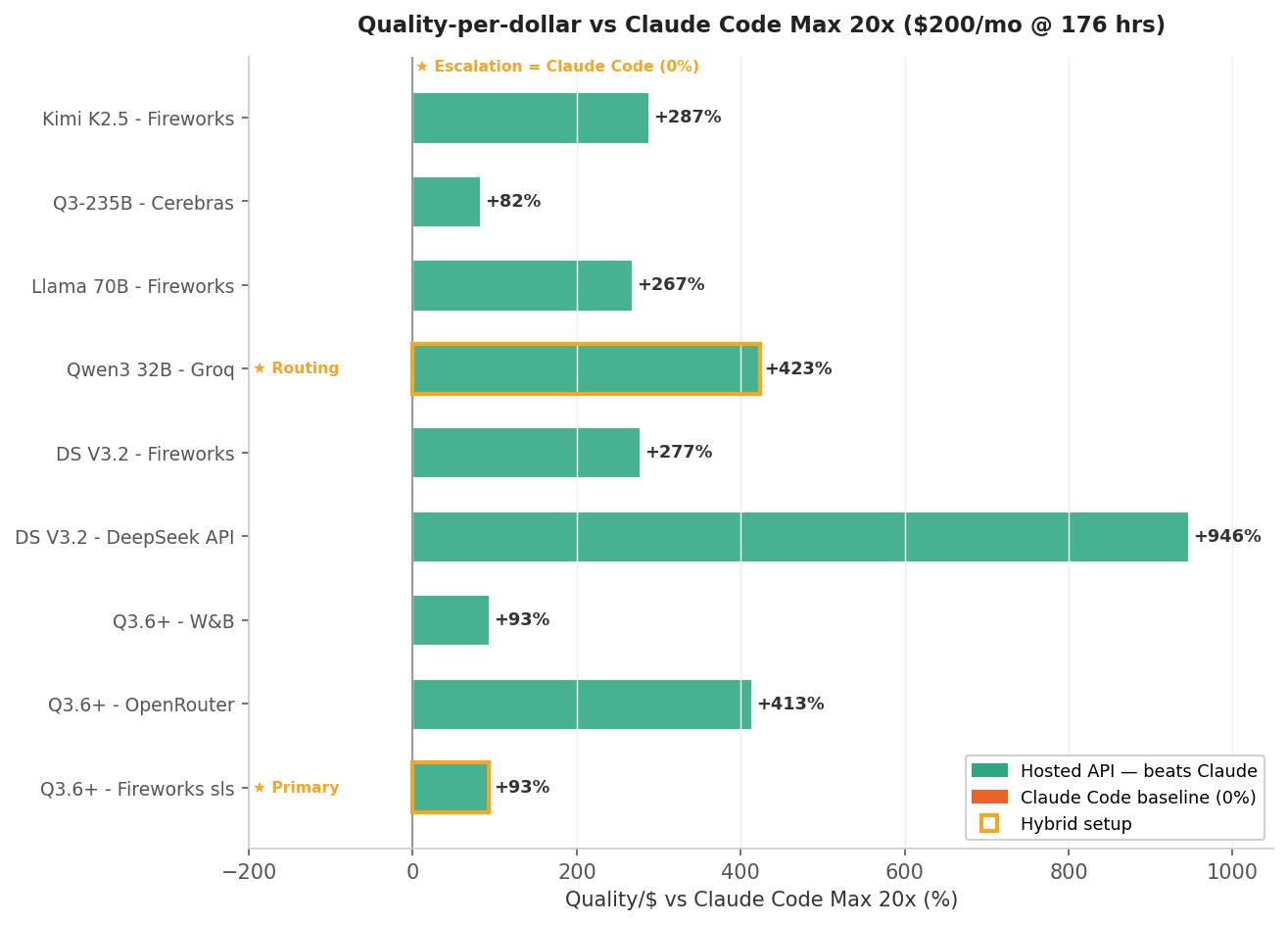
The hosted inference APIs absolutely dominate on this metric. When you're paying $0.09–0.56/hr in per-token costs vs Claude Code's effective $1.14/hr, the math is brutal even with a quality gap.
But this chart is misleading if you only look at Q/$. A cheap model that needs twice as many turns to finish a task isn't actually cheaper. That's what the next chart shows.
Wall-clock time for a 30-turn coding task
This is what you actually feel as a developer. How long does it take to complete a real agentic coding task (plan → edit → test → fix, 30 turns)?
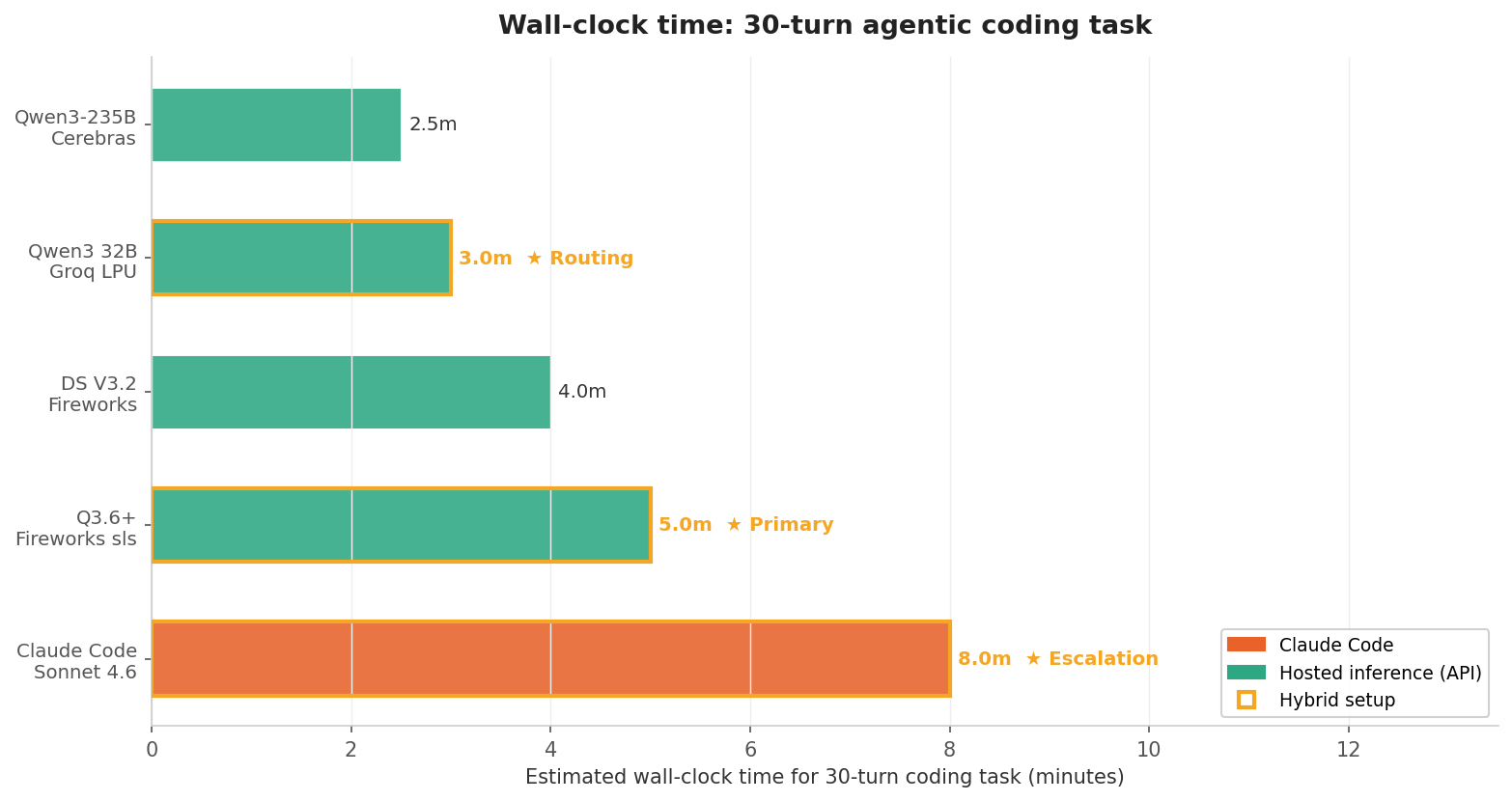
Cerebras and Groq finish in ~2.5–3 minutes. Claude Code takes ~8 minutes. But here's the catch:
A fast wrong answer costs more than a slow right one. Each failed tool-call or hallucinated edit triggers a correction loop which means 3–5 extra turns that erase the speed advantage.
"First-try-right rate" is the percentage of agent turns where the model's output is correct on the first attempt, with no retry or follow-up correction needed. A high first-try-right rate means fewer actual turns to complete a task. A low one means the model is fast but keeps generating work for itself. (The rates used here are estimates from my own test runs; they'll vary by codebase and task type.)
That gives us a more honest speed formula:
To make it concrete: the benchmark task is defined as 30 canonical steps (plan, edit, test, fix cycles). Claude Code completes those steps in ~22 actual turns — its ~85% first-try-right rate means fewer retries, and it regularly combines multiple steps (e.g., edit + test) into a single turn. Groq's Qwen3 32B runs at ~662 tok/s but its ~60% first-try-right rate stretches the same 30-step task to ~45 actual turns. Run the formula and the speed advantage shrinks dramatically: Groq still finishes faster in wall-clock time, but nowhere near what the ~7.4× raw tok/s ratio would suggest.
With that context, here's the full data across every stack I tested.
The full matrix
Hosted inference providers + Hermes Agent
Pricing assumes ~500K tokens/hour (3:1 input:output ratio, 15–40 turns per task).
The "Tool format" column shows which tool-call transport Hermes Agent selects internally for each model — this is not a field you configure. hermes is the native format used by Qwen and Hermes 3 models, with the lowest overhead and best reliability. deepseek_v31 is DeepSeek's tool-call dialect. llama3_json is a JSON-based fallback that works with most models but has slightly higher error rates on malformed outputs. anthropic is the Anthropic Messages API format used by MiniMax — Hermes Agent routes MiniMax through its anthropic_messages transport regardless of which provider you access it through.
| Model | Provider | Quality | SWE% | TTFT | tok/s | $/hr | Tool format | Best for |
|---|---|---|---|---|---|---|---|---|
| Qwen3.6 Plus | Fireworks serverless | 8.7 | ~72 | ~220ms | ~180 | $0.56 | hermes | Best quality + lowest latency |
| Qwen3.6 Plus | OpenRouter | 8.7 | ~72 | ~280ms | ~150 | $0.21 | hermes | Best quality, budget-friendly |
| Qwen3.6 Plus | W&B Inference | 8.7 | ~72 | ~300ms | ~140 | $0.56 | hermes | Integrated logging |
| DeepSeek V3.2 | Fireworks | 7.6 | ~74 | ~200ms | ~280 | $0.25 | deepseek_v31 | Reasoning + fast |
| DeepSeek V3.2 | DeepSeek API | 7.6 | ~74 | ~300ms | ~150 | $0.09 | deepseek_v31 | Absolute cheapest |
| Qwen3 32B | OpenRouter (Groq) | 7.6 | ~62 | ~100ms | ~662 | $0.18 | hermes | Fastest throughput |
| Qwen3-235B MoE | Cerebras (WSE) | 7.8 | ~65 | ~150ms | ~450 | $0.53 | hermes | Peak throughput |
| Kimi K2.5 | Fireworks | 7.8 | ~77 | ~180ms | ~389 | $0.25 | llama3_json | SWE-bench sleeper |
| MiniMax M2.7† | OpenRouter | 7.8 | ~78 | ~2100ms* | ~45 | $0.26 | anthropic | High-volume coding tasks |
| MiniMax M2.5 | OpenRouter | 7.6 | ~80 | ~1800ms* | ~65 | $0.17 | anthropic | Highest SWE-bench Verified |
| Qwen3 30B (A3B) | Fireworks | 7.5 | ~62 | ~170ms | ~250 | $0.25 | hermes | Budget MoE |
| Llama 3.3 70B | Fireworks | 7.4 | ~58 | ~180ms | ~280 | $0.25 | llama3_json | Stable mid-tier |
| Llama 3.3 70B | Together AI | 7.4 | ~58 | ~200ms | ~250 | $0.25 | llama3_json | Widest catalog |
*MiniMax TTFT includes reasoning time — not comparable to other entries.
†M2.7 is non-commercial licensed; earlier M2 models were MIT. Verify before commercial use.
Claude Code baseline (for comparison)
| Model | Provider | Quality | SWE% | TTFT | tok/s | $/hr | Best for |
|---|---|---|---|---|---|---|---|
| Claude Sonnet 4.6 | Claude Code Max 20x | 9.2 | ~80 | ~500ms | ~90 | $1.14 | Complex multi-file refactors |
The $/hr figure is the effective rate at 176 coding hours per month (a standard full-time developer month). The plan itself is a flat $200/mo regardless of usage.
Cost vs Claude Code at different utilization levels
The economics shift dramatically based on how many hours per month you're actually coding. Abbreviations: Q3.6+ = Qwen3.6 Plus, DS = DeepSeek.
| Combo | $/hr | 80 hrs/mo | 120 hrs/mo | 176 hrs/mo | 220 hrs/mo |
|---|---|---|---|---|---|
| Claude Code Max 20x | $1.14* | $200 | $200 | $200 | $200 |
| Q3.6 Plus · Fireworks | $0.56 | $45 | $67 | $99 | $123 |
| Q3.6 Plus · OpenRouter | $0.21 | $17 | $25 | $37 | $46 |
| DS V3.2 · DeepSeek API | $0.09 | $7 | $11 | $16 | $20 |
| Qwen3 32B · OpenRouter | $0.18 | $14 | $22 | $32 | $40 |
*Claude Code $/hr is the effective rate at 176 hrs/mo (full-time). At 80 hrs/mo it's $2.50/hr; at 220 hrs/mo it's $0.91/hr. The monthly cost is always $200 regardless.
At 80 hrs/mo (part-time), every single option is cheaper than Claude Code. At 176 hrs/mo (full-time), the hosted inference APIs are still 51–92% cheaper — 51% for Fireworks at $0.56/hr up to 92% for DeepSeek at $0.09/hr.
My recommendations
The hybrid approach (what I'd actually run)
- Primary backend: Qwen3.6 Plus via Fireworks serverless for complex coding tasks
- Fast routing model: Qwen3 32B via OpenRouter (Groq-hosted) for simple file reads, terminal commands, and skill lookups
- Escalation: Claude Code for the genuinely hard multi-file refactors where first-try-right matters most
Hermes Agent's /model command lets you switch providers mid-session with conversation history preserved. More importantly, Hermes Agent has a built-in fallback_model feature that automatically switches to a backup provider if your primary fails — rate limits, server errors, auth failures — without dropping your session. That's the answer to the outage problem that started this whole investigation. Configure it once and you're no longer dependent on any single provider's uptime.
If quality is the only thing that matters
Claude Code on Max 20x
Quality 9.2 | $200/mo flat | SWE-bench ~80%
Nothing in the open-weight ecosystem matches the tight co-optimization between Claude Code's harness and model. The $200/mo is worth it for complex refactors and architectural work where first-try-right matters most.
If you want the best quality with lowest latency
Qwen3.6 Plus via Fireworks serverless
Quality 8.7 | ~$0.56/hr | SWE-bench ~72%
Only 0.5 points behind Claude Code. Direct to Fireworks serverless — pay-per-token, no idle cost, and no aggregator routing overhead. Note that Qwen3.6 Plus is a closed model (Alibaba/Qwen), not open-weight, despite being available via Fireworks' serverless API.
Fireworks vs OpenRouter: which to use
| Fireworks serverless | OpenRouter | |
|---|---|---|
| Cost | ~$0.56/hr | ~$0.21/hr |
| TTFT | ~220ms | ~280ms |
| Latency overhead | None (direct) | Extra routing hop |
| API key setup | Inline in config.yaml |
In ~/.hermes/.env |
| Model switching | Requires config change | Single key, swap model ID |
| Provider reliability | Single provider — use fallback_model |
Built-in cross-provider routing |
| Model catalog | Fireworks models only | Hundreds of models |
Use Fireworks if latency is a priority. Pair it with a fallback_model pointing at OpenRouter so a Fireworks outage doesn't kill your session. Use OpenRouter alone if you want built-in cross-provider resilience without managing two configs.
If speed is your primary concern
Cerebras with Qwen3-235B for peak throughput
Quality 7.8 | $0.53/hr | ~450 tok/s
Groq with Qwen3 32B for lowest latency
Quality 7.6 | $0.18/hr | ~662 tok/s
Both make 30-step tasks feel near-instantaneous, but the lower quality scores mean more correction turns. Check the effective speed formula above before assuming faster tokens equals faster tasks.
If your work is mostly bug fixes and issue-driven tasks
Kimi K2.5 via Fireworks
Quality 7.8 | $0.25/hr | SWE-bench ~77%
Strong SWE-bench score (~77%) for a model at this price point. The composite quality score of 7.8 understates it for bug-fix work because SWE-bench is only 30% of the composite — the llama3_json tool format drags down the other factors. If most of your work looks like "fix this bug" or "implement this issue", it's worth benchmarking against Qwen3.6 Plus on your own tasks before assuming the composite score tells the whole story.
If budget is the only constraint
DeepSeek V3.2 via DeepSeek API
Quality 7.6 | $0.09/hr | SWE-bench ~74%
A full month of coding costs ~$16. Strong reasoning capability for the price.
Getting started
For the best balance of quality and latency, use Qwen3.6 Plus via Fireworks serverless — pay-per-token, no idle cost. If you'd rather trade a little latency for a lower bill, OpenRouter routes the same model at $0.21/hr with no additional config.
1. Install Hermes Agent
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
source ~/.zshrc # or ~/.bashrc
2. Add your API key
For OpenRouter, add to ~/.hermes/.env:
OPENROUTER_API_KEY=your_key_here
For the Fireworks serverless route, the key goes directly in config.yaml via the api_key field (shown in step 3).
3. Configure your model
Edit ~/.hermes/config.yaml. Two options worth using, plus a third listed for completeness:
Option 1 — Fireworks serverless (recommended — lowest latency):
model:
default: "accounts/fireworks/models/qwen3p6-plus"
provider: "custom"
base_url: "https://api.fireworks.ai/inference/v1"
api_key: "fw_your_api_key_here"
Direct to Fireworks, pay-per-token, no idle cost. ~$0.56/hr at typical agentic coding token volumes. Add a fallback_model block to automatically switch to OpenRouter if Fireworks goes down:
model:
default: "accounts/fireworks/models/qwen3p6-plus"
provider: "custom"
base_url: "https://api.fireworks.ai/inference/v1"
api_key: "fw_your_api_key_here"
fallback_model:
provider: "openrouter"
model: "qwen/qwen3p6-plus"
Hermes Agent activates the fallback automatically on rate limits, server errors, or auth failures — without dropping your session or losing context.
Option 2 — OpenRouter serverless (lower cost, small latency tradeoff):
model:
provider: "openrouter"
default: "qwen/qwen3p6-plus"
Routes to the same model at $0.21/hr. Worth it if you're cost-sensitive and the extra ~60ms TTFT doesn't matter.
Option 3 — Fireworks dedicated deployment:
If you have a dedicated Fireworks deployment, the config looks like this. Read the warning before using it.
Warning: A dedicated deployment of Qwen3.6 Plus on Fireworks bills at ~$48/hr continuously for this model, whether you're actively using it or not. For agentic coding, where sessions are bursty and you're frequently idle between runs, this is almost certainly the wrong cost model. A single idle overnight would cost more than a full month of the OpenRouter serverless route. The dedicated deployment only makes sense if you're running a production pipeline with near-continuous, high-throughput traffic — not personal dev work.
model:
default: "accounts/YOUR_ACCOUNT/deployments/YOUR_DEPLOYMENT_ID"
provider: "custom"
base_url: "https://api.fireworks.ai/inference/v1"
api_key: "fw_your_api_key_here"
context_length: 262144
The upside: a 256K token context window and lower latency than the serverless route. The tradeoff is the cost model — you're paying for reserved capacity, not usage.
4. Run it
hermes
That's enough to get a working session. To switch to Groq for lower-latency tasks, route through OpenRouter — it carries Groq-hosted models and you're already set up with an OPENROUTER_API_KEY:
model:
provider: "openrouter"
default: "qwen/qwen3-32b"
Use the /model command mid-session to switch providers without losing conversation history.
Full configuration reference and provider-specific options are in the Hermes Agent docs.
Where this leaves me
Six months ago I wouldn't have seriously considered replacing Claude Code for day-to-day work. The quality gap was too wide and the tooling friction too high. That's changed. The alternative model ecosystem has moved faster than I expected. Qwen3.6 Plus at quality 8.7 would have been a remarkable result for a frontier model a year ago, and now it runs on Fireworks' serverless API at ~$0.56/hr pay-per-token with no dedicated infrastructure to manage.
That said, Claude Code still earns its place. The 0.5-point quality gap is small on paper but meaningful in practice when a wrong edit triggers a 10-minute debugging loop. For greenfield work, simple tasks, and anything I'd consider routine, I've switched to Qwen3.6 Plus via Fireworks serverless as my default. For the genuinely complex sessions (deep architectural changes, unfamiliar codebases, anything where I really can't afford extra correction turns), Claude Code stays in the rotation.
The hybrid setup I described above is what I'm actually running. It's not theoretical.
Methodology
These are the definitions behind every number in the tables above.
- Quality score (1–10): Weighted composite of SWE-bench Verified (30%), tool-use reliability (25%), Aider Polyglot results (15%), multi-file edit coherence (15%), Hermes ecosystem compatibility (15%).
- Speed data: TTFT and tok/s from Artificial Analysis benchmarks, TokenMix latency reports (April 2026), and provider-published figures.
- Cost data: Per-token API pricing from provider docs. Claude Code assumes Max 20x at $200/mo.
- Token budget assumption: ~500K tokens/hour, 3:1 input:output ratio, 15–40 turns per agentic coding task.
All scores represent the model running through Hermes Agent, not raw model benchmarks. The harness overhead is real and varies by model.
Built with data from SWE-bench, Artificial Analysis, TokenMix, provider documentation, OpenRouter LLM Rankings (programming category, as of April 15, 2026), OpenRouter Hermes Agent usage (as of April 15, 2026), and MiniMax model pages (as of April 15, 2026). Updated April 15, 2026.